前回のエントリで、「 なんで世にあるアプリケーションは1バイトで済むUTF-8を3バイト表現でもOKなんて勘違いをするの?」って書いたけど、なんでかを考えてみた。
きっかけは、コメント
きっかけは、id:kick123からもらったコメント
「C2〜DFはC0〜DF?」ってところですが、1バイトで表現できるのは7ビットまでで、80を表現するには8ビットが必要です。
2バイト表現にあてはめるなら、「1100 0010」と「1000 0000」になり、1バイト目はC2になる。
ってことではないですか?
これ、最初「???」って感じだったんです。
理解するために、とりあえず「UTF-8で1byteで表せる文字一覧」を作ってみる。
utf-8_mapping_1byte posted by (C)ITOH Takashi

これ出すのに使ったプログラムは、PHPで
<?php for ($i=0; $i<=base_convert("01111111", 2, 10); $i++){ printf("\"%s\" , \"0%07s\" , \"%04s\" , \"%s\"\n", $i, base_convert($i, 10, 2), base_convert($i, 10, 16), hex2bin(strval(base_convert($i, 10, 16)))); } function hex2bin($hex_str) { return pack("H*" , $hex_str); }
で、この次が知りたい。
1byteで表せる範囲は分かった。じゃあ、この次にどうくるのか?
当然、2進数で「01111111」なので次は、「11111111」・・・・と行きたいところなんだけど、UTF-8の1byteではこの表現は取れない。
じゃあってんで、2byte使うことにする。UTF-8の2byte表現は、前回のエントリに書いたとおり
- 最初の1byteは、110xxxxx という形式にする
- 次の1byteは、 10xxxxxx という形式にする
ここで、注目しなければならないのは、「次の1byteで自由に使えるのは6桁まで」ということ。なぜ注意しなければならないか?
それは、さっきの1byte表現UTF-8で既に7桁目を使っているからである。
つまり、2byteを使って129個目のUTF-8文字を作る時には、次のように考える
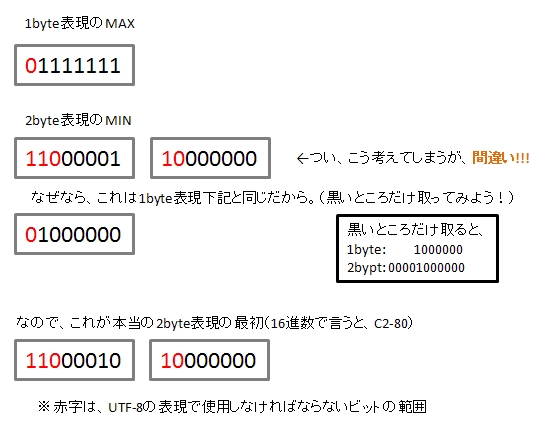
UTF-8の2byte最初の1文字 posted by (C)ITOH Takashi
なるほど、id:kick123のとおりUTF-8の2byte表現の最初の1byteは「C2」からでなければならない。
ここで、「なぜ、2通りの表現の仕方があるのか?」に気づく
ここで、ハタと気がついた。
2byteのUTF-8文字で、最初の1byteが「11000000」だったり、「11000001」だったりするUTF-8文字って「あってはならない」ものなんじゃないか?
あってはならない・・・・しかし、ありえる。
と。
ためしにやってみる。PHPで。
ターゲットは、1byte表現が01...で始まるものなら何でも良いんだけど、さっきの一覧表からとりあえず「z」をターゲットにする。1byte表現は「 "01111010"」
<?php $n = base_convert( "01111010" , 2, 16); echo hex2bin(strval($n))."\n";
は、確かに

と出る。当然だ。
で、次は、この2byte表現。「11000001」「10111010」を確かめてみる
<?php $n = base_convert( "11000001"."10111010" , 2, 16); echo hex2bin(strval($n))."\n";
も、やっぱり
と出る!!
ただし、前回の記事のように、これが本当に「z」なのかを確かめてみる
<?php $n = base_convert( "01111010" , 2, 16); echo hex2bin(strval($n))."\n"; $n = base_convert( "11000001"."10111010" , 2, 16); echo hex2bin(strval($n))."\n";
と、

EUCではあれだったけど、ShiftJISでは違った結果が出た。
じゃあ、アプリは何で?って話。
前回のエントリで不明だった「なんでそんな勘違いをしてしまうのか?」って点。
ここまで自分で手を動かしてデコードしてやっとわかった。
それは、多分おおよそのアプリケーションは、「UTF-8の定義部分を削除して、意味のある部分だけをガッチャンコしてデコードしている」からじゃないか?
ということ。
こんな感じ。応用すれば、どんな文字でも行ける。
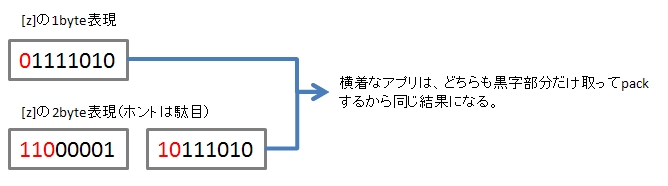
クリップボード05 posted by (C)ITOH Takashi
まぁ、これそもそもサーバサイドでチェックすべき項目かっていうと、自分自身としては「ブラウザなりのアプリの解釈がトロくさいことやってる」と思うんで、ブラウザ側で異常なUTF-8は異常なまま表示させてくれよーって思うけど、まぁそんなこと言ってもサーバ側の対応もやんなきゃいけないことだよね、PHPでも。このあたりはサーバサイドとクライアントサイドと開発者はお互い様ってことで。
しかし、UTF-8をDefineしたときは、こんな穴があるなんて思いもしなかったんだろう。
だけど、自分みたいなぺーぺーがこのコードの成り立ちを理解しようとすると「ハタ」と気付いてしまって、「じゃあ・・・」って思ったりするんだな。初心者目線大切。